

グーグルのクロールを回避したい状況に初めてなりました。
むしろ今まで、
「どうやってグーグルにインデックスされるか?」
の方に力を入れていたので、完全に盲点。
知識が無いのでグーグルさんのクロールを回避する方法を調べて実践してみました。
グーグルにクロールされたくない理由
簡単に背景を説明すると、
ワードプレスの操作や構築手順を人に教える動画を撮影するために、当サイトの特定のディレクトリ内に新たなワードプレスを導入しました。
やっていい事やダメなことを盛り込もうとすると、グーグルさんにクロールされるのが都合が悪いんです(苦笑)
しかも、間違ってドメイン全体のクロールを回避してしまうと、サイト自体が死亡してしまう危険性もあります。(怖っ)
なので、グーグルのクロールを、特定のディレクトリのみ(←重要)で回避する方法を調べて実践しました。
グーグルのクロールを回避するための作業手順
作業手順はこうです。
- クロールから回避しようとしているサイトが、すでにインデックスされていないか確認する
- robots.txtをグーグルさんのサーチコンソール上から確認する
- robots.txtを用意する
- robots.txtを目的の形にカスタマイズする
- FTPを用いて、ドメインのルートに置く
- robots.txtの更新をグーグルさんのサーチコンソール上から確認する
とにかく、
- グーグルのクロールが来れないようにする
- クロール来ても帰るようにする
のどちらかの施策が必要でした。
さらに言うと
・特定のディレクトリ(新規にワードプレスを置いた場所のみ)のみで作用し、メインのサイトに影響しない
という条件も必須です
検索した結果このような記載のあるサイトを見つけました。
robot.txtを使ってクローラーを制御する
robots.txtは、クローラーによるWebサイトへのアクセスを一括で制御できる。あるディレクトリのみインデックスされないように制御するといったことも可能でなのだ。robots.txtというファイルを作成し、以下のような必要な制御情報を記述して、サーバーのルートディレクトリにファイルを置こう。
(省略)サイト全体をインデックスしない場合
Disallow: /
新規制作のWEBサイトを構築しているときに使用することになるだろう。
指定したディレクトリのみをインデックスしない場合
Disallow: /ディレクトリ名/
たとえば、Disallow: /test/指定したページのみをインデックスしない場合
Disallow: /ディレクトリ名/ページ名(ファイル名)
たとえば、Disallow: /test/testpage.html
参照:テストページは要注意!noindexとrobots.txtでインデックス防止(http://cobitospice.com/hp/how-to-use-noindex-robots)
これを参考にして、
robots.txtを作成して、該当するディレクトリのみをクロール対象から外す
を行います。
今回の場合、URLをツイートしてしまい、すでに検索エンジンにインデックスされている可能性もありますので、そのインデックスの有無、そして、場合によりそのインデックス削除までを行います。
クロールから回避しようとしているサイトが、すでにインデックスされていないか確認する
これはものすごく簡単な作業で、
該当するページのURL、例えば当ページであれば
”https://shiomi-koshi.com/google-1306”
この頭に
site:
と付け加えて、
”site:https://shiomi-koshi.com/google-1306”
検索エンジンで検索してあげればいいだけです。
グーグルさんとヤフーさんで検索してみましたが、今回はどちらも該当なしでした。
↓↓↓こんな感じ↓↓↓
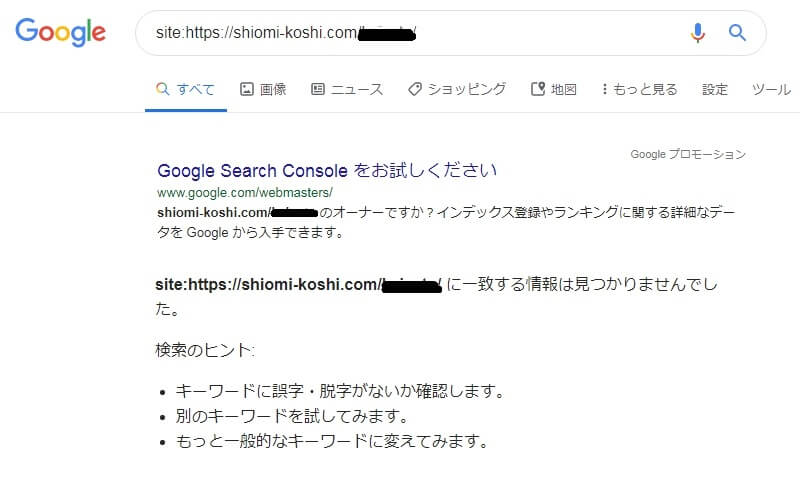
(むしろこちらが本来の目的)
robots.txtをグーグルさんのサーチコンソール上から確認する
こちらはサーチコンソールの標準機能です。
既にサーチコンソールに認識されているrobots.txtがある場合に、robots.txtの内容を表示できます。
【手順】
おそらくサーチコンソールが新バージョンになっているので、旧バージョンで表示します。
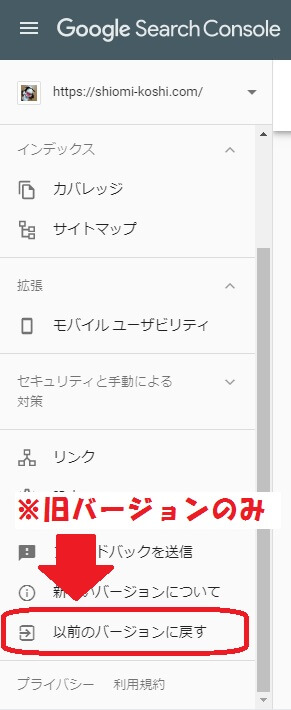
続いて、旧バージョンのサーチコンソールから「クロール」⇒「robots.txtテスター」を選びます。
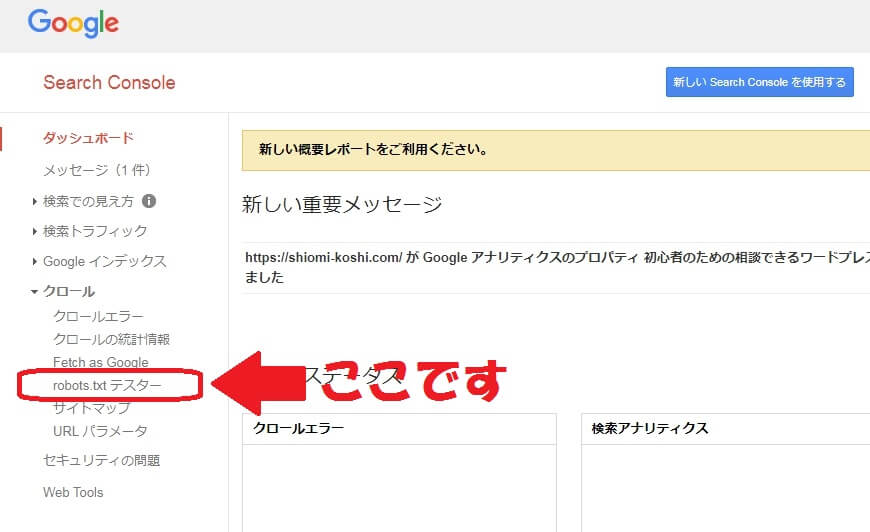
僕の場合作った記憶はないのですが、すでにファイルが存在していました(苦笑)

正直良くわかりませんが、気にせず進めます。
robots.txtを用意する
今回はすでにあったので作りませんでしたが、一般的なテキストエディタで
robots.txt
という名前のファイルを作成すればOKです。
robots.txtを目的の形にカスタマイズする
User-agent: * ←必須。考える必要なし
Disallow: /wp-admin/ ←なくてもいい
Disallow: /★URL★/ ←今回の目的
Sitemap: https://shiomi-koshi.com/sitemap.xml ←サイトマップの位置
とりあえずこの形式で作成しました。
サイトマップなどは間違って僕の物をコピペしないように注意してください(笑)
赤色以外の部分は無くても問題ありません。
FTPを用いて、ドメインのルートに置く
ココはちょっとテクニカルな話になるので分からなかったら諦めてください(笑)
FTPというツールを使って、作成した「robots.txt」をサーバー上に置く必要があります。
最近は使ってない人もいるようなので、そこはなんとかしてください(笑)
また気が向いたら記事にします。
ルートというのは専門用語です。
ざっくり言うとサーバーの一番上のフォルダのことを言います。
例えば
◎◎.com/ushi/milk/oisii
というURLで運用されているならば、ルートは
◎◎.com
というフォルダのことを指します。
ただ、ここの【ドメインのルート】というのは、ワードプレスの置いてある場所です
FTPで見える
/ドメイン名/public_html
という場所が該当します。(注意!:ドメイン名のフォルダではない)
ここに、先ほど作成したrobots.txtを置きます

こういう感じ↑↑↑
実は最初に検索した参考サイト様の
サーバーのルートディレクトリにファイルを置こう。
は、厳密には間違いです。(多分専門の人ではないんでしょう)
分かる方はご注意くださいませ。
robots.txtの更新をグーグルさんのサーチコンソール上から確認する
再度先ほどのツールを使って確認します。
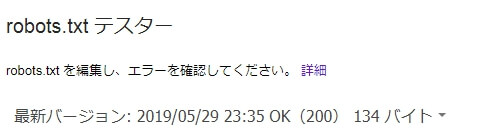
最新バージョン:の日付がファイルの編集日時とあっていればOKです。
グーグルのクロールを回避するのは意外と楽w
はじめてのグーグルクロールの回避ということで、かなりの労力を想定していましたが
実際やってみると、全然大したことありませんでした。
同じような用途でこの操作が必要な方がいらっしゃるかも?と思い、まれなケースとは思いつつ。
この記事を仕上げました。
どうしても検索されたくないページがある場合はさくっとやってみましょう!(笑)
悩んだらサイドバーのLINE@から相談してくださいね!


コメント